Ниже приводится решение всех вопросов для подготовки к аттестации 1С:Профессионал по технологическим вопросам. Текстов самих вопросов и вариантов ответов нет. Предполагается, что у вас имеется книга «Комплект вопросов сертификационного экзамена «1С:Профессионал» по технологическим вопросам с примерами решений». Я ни в комем случае не призываю заучивать ответы, а рекомендую прорешивать и анализировать каждый вопрос, ведь сдача данного экзамена, это лишь первый шаг к сертификации 1С:Эксперт по технологическим вопросам.
Все решения авторские, потому любые замечания, предложения и критика только приветствуется. Все ответы проверены на сайте учебного тестирования.
В данной стате представлены решения раздела №5
«Производительность».
05.01 — 1
Если операция чаще всего выполняется в веб клиенте, нужно обязательно проверить скорость её выполнения в тонком клиенте и в различных браузерах.
Основной задачей будет: понять, НА ЧТО уходит большая часть времени выполнения операции.
В первую очередь предлагается получить:
- время выполнения операции по секундомеру,
- замер конфигуратором с серверной частью,
- время выполнения всех запросов в однопользовательском режиме от одного выполнения операции.
Источник:
05.02 — 2
-debug -<режим> — Запуск кластера серверов в режиме отладки конфигураций. Параметр <режим> указывает, с использованием какого протокола будет функционировать отладчик на данном кластере серверов:
- -tcp ‑ протокол TCP/IP;
- -http ‑ протокол HTTP.
Значение по умолчанию: -tcp.
В связи с тем, что в режиме отладки производительность сервера падает, рекомендуется использовать отладочный режим только для тех серверов, на которых выполняется отладка.
Источник:
Смотрите также:
…
Для получения замера производительностью с серверной частью нужно перевести кластер серверов в режим отладки конфигураций. В разделе «4.1. Запуск агента сервера» ИТС указывается, что ключ -debug используется для запуска кластера серверов в режиме отладки конфигураций. Если сервер запущен в режиме сервиса, то требуется отредактировать строку запуска сервиса ОС Windows. Таким образом, для получения замера производительностью нужно внести в реестр Windows (regedit) ключ «-debug» в строку запуска службы агента 1С:Предприятия.
Источник:
- Комплект вопросов сертификационного экзамена»1С:Профессионал» по технологическим вопросам с примерами решений. Раздел 2. Примеры экзаменационных заданий.
- http://v8.1c.ru/metod/books/book.jsp?id=492
05.03 — 1
Оценка производительности и оптимизация многопользовательской системы. Общий подход.
Перед началом работ по оптимизации системы необходимо всегда получать начальную оценку производительности при помощи «Оценки интегральной производительности системы по методике APDEX«.
Источник:
05.04 — 1
В документации на сайте 1С:ИТС в части работы технологического журнала ничего не сказано об отличиях для 32-разрядной и 64-разрядной системы Windows.
Документация:
05.05 — 2
Дисперсией случайной величины X называется математическое ожидание M квадрата отклонения случайной величины от ее математического ожидания

Слово «дисперсия» означает «рассеяние», т.е. дисперсия характеризует рассеяние (разбросанность) значений случайной величины около ее математического ожидания.
Из определения следует, что дисперсия – это постоянная величина, т.е. числовая характеристика случайной величины, которая имеет размерность квадрата случайной величины.
С вероятной точки зрения, дисперсия является мерой рассеяния значений случайной величины около ее математического ожидания.
Источник:
Шпаргалка:
- Математическое ожидание — сумма произведений всех возможных значений случайной величины на вероятности этих значений.
- Оценка математического ожидания — среднее арифметическое значение случайной величины.
- Мода — наиболее вероятное значение случайной величины (значение, в котором плотность вероятности максимальна).
- Медиана — такое значение случайной величины, при котором равновероятно, окажется ли случайная величина больше или меньше этого значения.
- Центрированная случайная величина — отклонение случайной величины Х от ее математического ожидания.
- Дисперсия — математическое ожидание квадрата соответствующей центрированной величины.
- Стандартное отклонение — оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии.
05.06 — 3
Плохая работа запроса для СУБД MS SQL проверяется так: включив профайлер SQLServer, выполняем ключевую операцию еще раз, и собираем длительности всех запросов, выполнявшихся во время его работы (показатель duration). Если сумма duration близка к времени выполнения всей операции, можно однозначно делать вывод, что потери времени происходят в СУБД. Дальнейшее исправление состоит в определении неоптимальностей и их устранении. Для измерения длительности запроса в других СУБД (не MS SQL Server) рекомендуется использовать технологический журнал«1С».
Источник:
- Е. В. Филиппов «Настольная книга 1С:Эксперта по технологическим вопросам», стр. 23
- http://v8.1c.ru/metod/books/book.jsp?id=452
05.07 — 1
Величина, равная квадратному корню из дисперсии, называется стандартным отклонением (sx), т.е.:

Совершенно очевидной интерпретацией стандартного отклонения является его способность оценивать «типичность» среднего: стандартное отклонение тем меньше, чем лучше среднее суммирует, «представляет» данную совокупность наблюдений.
Источник:
Шпаргалка:
Среднеквадратическое отклонение (синонимы: … стандартное отклонение …) — в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания.
Источники:
…
- Математическое ожидание — сумма произведений всех возможных значений случайной величины на вероятности этих значений.
- Оценка математического ожидания — среднее арифметическое значение случайной величины.
- Мода — наиболее вероятное значение случайной величины (значение, в котором плотность вероятности максимальна).
- Медиана — такое значение случайной величины, при котором равновероятно, окажется ли случайная величина больше или меньше этого значения.
- Центрированная случайная величина — отклонение случайной величины Х от ее математического ожидания.
- Дисперсия — математическое ожидание квадрата соответствующей центрированной величины.
- Стандартное отклонение — оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии.
05.08 — 5
Из всех представленных вариантов подходит только один — «Необходимо настроить технологический журнал с фильтрами, включающими уникальные части текста запроса, затем дождаться следующего выполнения запроса. При следующем выполнении стек запроса будет в технологическом журнале.»
05.09 — 3
Рассмотрим, как можно получить суммарное время выполнения всех запросов на примере MS SQL Server.
Для этого требуется собрать трассировку с помощью MS SQL Profiler по следующим классам событий от одного выполнения операции:
У перечисленных классов событий обязательно должны собираться данные по полю Duration, т.к. данные по этому полю необходимо будет проанализировать в первую очередь.
Рекомендуется всегда устанавливать фильтр по полям DatabaseName и/или DatabaseID.
Источник:
…
В разделе «Оценка производительности и оптимизация многопользовательской системы. Общий подход.» указывается, что для получения суммарного времени выполнения всех запросов на примере MS SQL Server требуется собрать трассировку с помощью MS SQL Profiler по следующим классам событий от одного выполнения операции:
- SQL:BatchCompleted
- RPC:Completed
Источник:
- Комплект вопросов сертификационного экзамена»1С:Профессионал» по технологическим вопросам с примерами решений. Раздел 2. Примеры экзаменационных заданий.
- http://v8.1c.ru/metod/books/book.jsp?id=492
05.10 — 5
Столбцы данных класса событий SQL:BatchCompleted:
- Reads — Число операций чтения страниц, вызванных пакетом.
- RowCounts — Количество строк, затронутых событием.
- Duration — Длительность события (в микросекундах).
Источник:
…
Наблюдаем высокую загрузку CPU по счетчикам Processor Time на сервере СУБД c MS SQL Server.
Что делать?
- Подключиться к серверу СУБД. Запустить MS Sql Server Management Studio
- Выяснить, какие именно базы создают наибольшую нагрузку на сервер СУБД за последний период (в течение которого наблюдается нагрузка). В этом примере период 1 час ’01:00:00.000′, его нужно будет изменить.
- Получаем список запросов, которые создали нагрузку за последний час, посчитанный по 10000 запросов. (Выполняется около 2 минут).
- Если нагрузка «размазана» по запросам, нужно настраивать трассировку
- Для этого на сервере должна быть директория для трассировки.
- Останавливаем трассировку, когда уверены, что трассировку собрали в интересующий период нагрузки.
- Сохраняем трассировку в тестовую БД test в таблицу trace, в которой будем анализировать загрузку.
- Добавляем в таблицу trace две колонки HashSQL varchar(4000) и HashSQLMD5 varbinary(32).
- Анализируем трассировку. Например, смотрим:
SELECT TOP 100
В целом эту же методику можно использовать для поиска по Reads, Writes, Duration, и т.д.
[HashSQL] as HashSQL
,SUM([CPU]) as SumCPU
,SUM([Reads]) as SumReads
,SUM([Writes]) as SumWrites
,SUM([Duration]) as SumDuration
,[DatabaseID] as DatabaseID
,SUM([RowCounts]) as SumRowCounts
FROM [test].[dbo].[trace]
WHERE [DatabaseID] = 12345
GROUP BY
[HashSQL]
,[DatabaseID]
ORDER BY SumCPU desc - Находим наиболее интересные запросы по SUM([CPU]).
- По технологическому журналу определяем лидера, исправляем.
Источник:
Смотрите также:
05.11 — 1
Центрированной случайной величиной, соответствующей случайной величины X называется разность между случайной величиной X и ее математическим ожиданием

Источники:
Шпаргалка:
- Математическое ожидание — сумма произведений всех возможных значений случайной величины на вероятности этих значений.
- Оценка математического ожидания — среднее арифметическое значение случайной величины.
- Мода — наиболее вероятное значение случайной величины (значение, в котором плотность вероятности максимальна).
- Медиана — такое значение случайной величины, при котором равновероятно, окажется ли случайная величина больше или меньше этого значения.
- Центрированная случайная величина — отклонение случайной величины Х от ее математического ожидания.
- Дисперсия — математическое ожидание квадрата соответствующей центрированной величины.
- Стандартное отклонение — оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии.
05.12 — 2
Математическое ожидание дискретной случайной величины – это сумма парных произведений всех возможных ее значений на соответствующие вероятности:

, где

Источники:
Шпаргалка:
- Математическое ожидание — сумма произведений всех возможных значений случайной величины на вероятности этих значений.
- Оценка математического ожидания — среднее арифметическое значение случайной величины.
- Мода — наиболее вероятное значение случайной величины (значение, в котором плотность вероятности максимальна).
- Медиана — такое значение случайной величины, при котором равновероятно, окажется ли случайная величина больше или меньше этого значения.
- Центрированная случайная величина — отклонение случайной величины Х от ее математического ожидания.
- Дисперсия — математическое ожидание квадрата соответствующей центрированной величины.
- Стандартное отклонение — оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии.
05.13 — 1
Пусть случайная выборка порождена наблюдаемой случайной величиной ξ:

математическое ожидание

и дисперсия которой

неизвестны. В качестве оценок для этих характеристик было предложено использовать выборочное среднее:

и выборочную дисперсию

Источники:
Шпаргалка:
- Математическое ожидание — сумма произведений всех возможных значений случайной величины на вероятности этих значений.
- Оценка математического ожидания — среднее арифметическое значение случайной величины.
- Мода — наиболее вероятное значение случайной величины (значение, в котором плотность вероятности максимальна).
- Медиана — такое значение случайной величины, при котором равновероятно, окажется ли случайная величина больше или меньше этого значения.
- Центрированная случайная величина — отклонение случайной величины Х от ее математического ожидания.
- Дисперсия — математическое ожидание квадрата соответствующей центрированной величины.
- Стандартное отклонение — оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии.
05.14 — 3
Модой дискретной случайной величины ξ называется ее значение, имеющее наибольшую вероятность.

Источники:
Шпаргалка:
- Математическое ожидание — сумма произведений всех возможных значений случайной величины на вероятности этих значений.
- Оценка математического ожидания — среднее арифметическое значение случайной величины.
- Мода — наиболее вероятное значение случайной величины (значение, в котором плотность вероятности максимальна).
- Медиана — такое значение случайной величины, при котором равновероятно, окажется ли случайная величина больше или меньше этого значения.
- Центрированная случайная величина — отклонение случайной величины Х от ее математического ожидания.
- Дисперсия — математическое ожидание квадрата соответствующей центрированной величины.
- Стандартное отклонение — оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии.
05.15 — 1
Режим замера производительности 1С:Предприятия 8 отображает, где исполнялся код на встроенном языке в клиент-серверной информационной базе: на клиенте или на сервере:
- строки кода на встроенном языке, исполнение которых происходило на клиенте, отображаются в замере производительности с помощью значка
 в колонке «Клиент»;
в колонке «Клиент»; - строки кода на встроенном языке, исполнение которых происходило на сервере, отображаются в замере производительности с помощью значка
 в колонке «Сервер».
в колонке «Сервер».
На приведенном ниже рисунке выделены колонки, в которых значками отображаются строки, исполнение которых происходило на клиенте и на сервере:
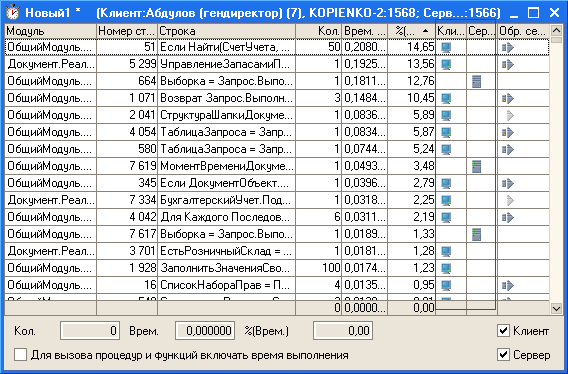
По колонкам «Клиент» и «Сервер» в замере производительности также возможна сортировка: для этого достаточно щелкнуть мышью в соответствующей колонке. При этом строки кода, исполнение которых происходило на клиенте или на сервере, будут сгруппированы.
Источники:
05.16 — 4
Медианой случайной величины ξ называется такое ее значение ![]() , относительно которого равновероятны получение большего и получение меньшего значения. Если — дискретная случайная величина, то
, относительно которого равновероятны получение большего и получение меньшего значения. Если — дискретная случайная величина, то ![]() — это число на отрезке
— это число на отрезке ![]() , для которого
, для которого

Источники:
Шпаргалка:
- Математическое ожидание — сумма произведений всех возможных значений случайной величины на вероятности этих значений.
- Оценка математического ожидания — среднее арифметическое значение случайной величины.
- Мода — наиболее вероятное значение случайной величины (значение, в котором плотность вероятности максимальна).
- Медиана — такое значение случайной величины, при котором равновероятно, окажется ли случайная величина больше или меньше этого значения.
- Центрированная случайная величина — отклонение случайной величины Х от ее математического ожидания.
- Дисперсия — математическое ожидание квадрата соответствующей центрированной величины.
- Стандартное отклонение — оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии.
05.17 — 5
Пусть производится многократное измерение физ. вел. Х в одних и тех же внешних условиях. При этом истинное знач-е вел-ны Х(ХИСТ) не известно, и в процессе измерений нах-ся оценка ХИСТ – ХДЕЙСТВ, которая при увеличении числа измерений приближается к её ист-му значению. В процессе измерений появляются знач-я Хmin ≤ Х ≤ Хmax . При этом производится некоторое количество измерений (например, п =50)
Находится интервал измерения Хmax— Хmin = ∆Х , который разбивается на К – равных промежутков (напр-р К = 5)
Определяется число значений измеряемой величины, попадающих в каждый интервал, и строится таблица:

Строится гистограмма случайной величины Х

Частота измеренных значений Х достигает максимума в районе середины, что указывает на то ,что где-то в приделах этого прямоугольника находится истинное значение измеряемой величины.
Появление измеряемых значений Х , как в сторону уменьшения, от центра распределения (влево), так и в строну увеличения значений Х (право), снижается

Частота появления тех или иных измеренных знач-й Х определяет вероятность получения тех или иных измеряемых значений.
При увеличении числа интервалов nK ступенчатая функция может быть заменена некоторой плавной кривой f(x), которая называется функцией плотности вероятности появление тех или иных измеренных значений величины Х, а dP = f(x)dx – вероятность показания тех или иных измеренных значений величины х в тот или иной интервал dx
При этом поведение ф-и f(x) практически повторяет ход гистограммы.
Явный вид функции f(x), т.е. вер-ти появления того или иного значения х в процессе измерения называется законом распределения случайной величины х.
Наиболее вер-е значение –Х1 — max f(x).
Особенности закона норм распределения:
- Имеется явно выраженный центр (мода) закона распределения
- Ход кривой функции f(x) симметричен относительно центра распределения, т.е вероятность появления измеренных значений величины х, симметричных относительно центра, становится одинаковой при большом числе измерений
- Рассеяние измеренных значений относительно центра уменьшается с уменьшением пар-ра σ, где σ – среднеквадратичное отклонение f(x), определяется по результатам измерений
Источники:
Таким образом, наличие нескольких пиков на гистограмме распределения говорит о некорректных данных замеров. Это может быть следствием того, что:
- Некорректно встроены счетчики замеров производительности
- С одним счетчиком выполняется несколько типов операций, длительность которых существенно различается
05.18 — 3
Медианой случайной величины ξ называется такое ее значение ![]() , относительно которого равновероятны получение большего и получение меньшего значения. Если — дискретная случайная величина, то
, относительно которого равновероятны получение большего и получение меньшего значения. Если — дискретная случайная величина, то ![]() — это число на отрезке
— это число на отрезке ![]() , для которого
, для которого

Графически медиана — это абсцисса точки, в которой площадь под кривой распределения делится пополам.

Если распределение унимодальное и симметричное, то математическое ожидание, мода и медиана случайной величины совпадают. Но в противном случае, медиана более устойчива к случайным «выбросам» замеров с большим абсолютным значением.
Источники:
05.19 — 1
Величина, равная квадратному корню из дисперсии, называется стандартным отклонением (sx), т.е.:

Совершенно очевидной интерпретацией стандартного отклонения является его способность оценивать «типичность» среднего: стандартное отклонение тем меньше, чем лучше среднее суммирует, «представляет» данную совокупность наблюдений.
Еще одно важное применение стандартного отклонения связано с тем, что оно, наряду со средним арифметическим, позволяет определить самые существенные характеристики нормального распределения. Графически нормальному распределению частот наблюдений соответствует, как известно, симметричная колоколообразная кривая. Свойства нормального распределения прекрасно изучены, что позволяет делать важные выводы относительно самых разных распределений, не обязательно нормальных.
В частности, известно, что 68% наблюдений (точнее, 68% общей площади) будет заключено в пределах ±1 стандартное отклонение от среднего значения. Если, скажем, среднее нормального распределения равно 200, а стандартное отклонение — 4, то можно заключить, что не менее 68% наблюдений лежит между значениями 196 и 204 (т. е. 200 ±4). Соответственно не менее 32% случаев будут лежать за этими пределами, в левом и правом «хвостах» распределения. Из теории вероятности известно также, что в пределах ±3 стандартных отклонений окажется около 99,73% общего числа наблюдений.
Очевидно, что стандартное отклонение — это прекрасный показатель положения любого конкретного значения относительно среднего.
Источники:
05.20 — 5
Режим замера производительности в 1С:Предприятии 8 позволяет успешно производить оптимизацию работы клиент-серверных приложений. Для выполнения такой оптимизации достаточно выполнить всего несколько действий, после чего проанализировать результаты замера производительности и перейти к улучшению кода на встроенном языке.
Первый шаг — выполнить замер производительности кода на встроенном языке, исполняемом на клиенте и на сервере. Получив результаты замера производительности, сохранить их в файл.
Второй шаг — проанализировать результаты замера производительности.
Проанализировать в результатах время исполнения функций на клиенте и на сервере. Выбрать и проанализировать функции, исполнение которых на клиенте и на сервере заняло максимальное количество времени. Это удобно сделать, отображая с помощью фильтра информацию только для клиента или только для сервера и выполняя сортировку по колонкам времени и процентов.
Проанализировать серверные вызовы: вызовы процедур и функций общих модулей на сервере, вызовы сервера при обращении к методам и свойствам объектов языка (обращение к базе данных, оперативная отметка времени и т.п.).
Проведенный анализ результатов замера позволит выявить узкие места в приложении даже без наличия большой тестовой базы и выполнения нагрузочного тестирования:
- обращения к серверу в цикле, запросы в цикле;
- обращения к свойствам объекта по ссылке;
- и другие.
Источник:
…
Замер производительности отладчиком «1С:Предприятие 8» позволяет оценить скорость работы кода конфигурации. Показывает количество использования конкретных строк кода и время их выполнения — чистое и в процентном отношении к общему времени работы.
Источники:
- Е. В. Филиппов «Настольная книга 1С:Эксперта по технологическим вопросам», стр. 116
http://v8.1c.ru/metod/books/book.jsp?id=452
05.21 — 3
При вызове методов: ПоместитьВоВременноеХранилище, ПоместитьФайл, НачатьПомещениеФайла, значения указанные в параметрах, записываются в сеансовые данные.
Источники:
…
Временное хранилище — это специализированное хранилище информации, в которое может быть помещено значение. Основное назначение — это временное хранение информации при клиент-серверном взаимодействии до ее переноса в базу данных. Механизм временного хранилища совместно с механизмом работы с файлами предоставляет набор, с помощью которого можно поместить данные, хранящиеся локально у пользователя, во временное хранилище информационной базы, перенести эту информацию из временного хранилища в базу данных и получить ее обратно на компьютер пользователя. Наиболее распространенные прикладные задачи, решаемые этими механизмами, -это хранение сопроводительной информации, например, изображений товаров, связанных с договорами документов и т. п. Механизмы временного хранилища и работы с файлами часто используются совместно, но могут использоваться и по отдельности. Временное хранилище, сформированное в одном сеансе, недоступно из другого сеанса. Исключением является возможность передачи данных из фонового задания в сеанс, инициировавший это фоновое задание, с помощью временного хранилища. В механизме работы с временным хранилищем есть возможность передать данные из фонового задания в сеанс, инициировавший фоновое задание. Для такой передачи следует в родительском сеансе поместить во временное хранилище пустое значение (с помощью метода ПоместитьВоВременноеХранилище()), указав какой-либо идентификатор создаваемого временного хранилища (параметр Адрес). Затем полученный адрес передать в фоновое задание через параметры фонового задания. Далее, если в фоновом задании этот адрес использовать в качестве значения параметра Адрес метода ПоместитьВоВРеменноеХранилище(), то результат будет скопирован в сеанс, из которого было запущено фоновое задание. Данные, помещенные во временное хранилище в фоновом задании, не будут доступны из родительского сеанса до момента завершения фонового задания. Данные, помещенные во временное хранилище прикрепляются к параметрам сеанса и помещаются в хранилище сеансовых данных.
Источник:
- Комплект вопросов сертификационного экзамена»1С:Профессионал» по технологическим вопросам с примерами решений. Раздел 2. Примеры экзаменационных заданий.
- http://v8.1c.ru/metod/books/book.jsp?id=492
05.22 — 2
В тексте запроса содержится информация, какие данные, из каких таблиц и по каким условиям требуется получить. Но каким образом выполнять запрос, «решает» сама СУБД. Для этого на основании текста запроса, имеющихся индексов таблиц и статистики оптимизатор СУБД строит план запроса – набор физических операторов, которые необходимо выполнить для получения запрошенных данных. Посмотреть, какой план запроса используется, можно через технологический журнал или средствами самой СУБД.
Источники:
05.23 — 3
Вложенный запрос (подзапрос) часто бывает нужен для того, чтобы отобрать по условию или каким-то образом сгруппировать данные реальной таблицы, прежде чем использовать их в соединении.
При написании таких запросов нужно помнить, что соединение с вложенным запросом может крайне замедлить выполнение запроса, сделать работу запроса нестабильной (чувствительной к используемой СУБД и аппаратуре) и вообще является потенциально опасным моментом для быстродействия системы.
Источники:
05.24 — 3
Для того чтобы узнать, какой план выполнения запроса выбран оптимизатором СУБД, можно воспользоваться консолью запросов, технологическим журналом или средствами СУБД. Как правило, запрос – сложный и будет плохо выполняться, если в скомпилированном плане выполнения запроса есть timeout warning, который означает, что оптимизатору СУБД не хватило времени на поиск наилучшего плана запроса.
Источники:
05.25 — 2
При разработке запросов нужно быть уверенным, что они использует эффективные планы выполнения запросов. Для сложных запросов СУБД с высокой вероятностью выберет неправильный план выполнения запроса, что особенно актуально для СУБД DB2, PostgreSQL и Oracle.
Для того чтобы узнать, какой план выполнения запроса выбран оптимизатором СУБД, можно воспользоваться консолью запросов, технологическим журналом или средствами СУБД
Источники:
Чтобы узнать, используется ли эффективный план запроса, необходимо получить и проанализировать план запроса вручную.
05.26 — 1
Чтобы представлять, как происходит поиск данных в таблицах, необходимо понимать, что структура индекса в СУБД представляет собой дерево значений проиндексированных полей. На первом уровне дерева находятся значения первого поля индекса, на втором – второго и так далее. Чтобы выполнить поиск данных по индексу, сначала необходимо провести поиск по значению первого поля индекса, затем – второго и так далее. Если, например, условие по первому полю индекса не указано, то индекс уже не сможет обеспечить быстрый поиск. Если указано условие по нескольким первым полям индекса, а затем одно или несколько полей индекса не задано, то индекс может быть использован только частично.
Таким образом, индексы будут использованы эффективно только в том случае, когда индекс покрывает условия запроса, то есть с самого начала содержит без пропуска поля, на которые накладываются условия.
Источники:
05.27 — 4
Не следует также создавать индексы по низкоселективным полям. Селективность индекса отражает процент записей, которые по условию можно выбрать из таблицы. Максимально высокая селективность индекса – у первичного ключа. Если реквизит имеет тип Булево, то индексировать его имеет смысл только в том случае, если незначительная часть записей таблицы всегда принимает одно значение (например, ЛОЖЬ) и нужно выбрать из таблицы записи с этим значением.
В целом к расстановке индексов в таблицах нужно подходить осмысленно, творчески и учитывать накопленный опыт, как личный, так и опыт функционирования подобных прикладных решений.
Источники:
…
Индексная селективность — отношение числа строк, соответствующих конкретному ключевому значению, к общему числу строк в индексе. Селективность индекса — это показатель того, сколько строк от общего числа приходится на одно ключевое значение индекса. Чтобы рассчитать селективность индекса достаточно посмотреть значение DISTINCT_KEYS в динамическом представлении ALL_INDEXES. Селективность чаще вычисляют в процентах. Чем больше этот процент, тем хуже селективность. Селективность хороша, если мало строк имеют одинаковые ключевые значения. Индексный доступ к данным имеет смысл при хорошей селективности. Таким образом, для низкоселективных полей процент отношения числа строк, соответствующих конкретному ключевому значению, достаточно высок. Как следствие использования индекса по низкоселективному полю на практике не помогает эффективно сократить мощность выборки для соответствия условиям поиска по индексу, и является более дорогой операций, чем поиск по полям с малым процентом отношения числа строк.
Источник:
- Комплект вопросов сертификационного экзамена»1С:Профессионал» по технологическим вопросам с примерами решений. Раздел 2. Примеры экзаменационных заданий.
- http://v8.1c.ru/metod/books/book.jsp?id=492
05.28 — 4
Для запросов в динамических списках даются следующие рекомендации:
Соединяться в запросе следует только с небольшим количеством реальных таблиц (в оптимальном варианте в динамическом списке – только одна таблица, и она назначена основной).
Не рекомендуется выполнять соединения:
- с большим количеством реальных таблиц. Ориентироваться стоит на количество не более 4 таблиц;
- с вложенными запросами;
- с виртуальными таблицами.
Источники: