![]() Всем привет. Сегодня я вам расскажу историю одной оптимизации или как я восстанавливал нормальную работу в <НазваниеКомпании>.
Всем привет. Сегодня я вам расскажу историю одной оптимизации или как я восстанавливал нормальную работу в <НазваниеКомпании>.
Симптомы были объявлены следующие: общая неудовлетворительная производительность системы: по простому «тормозит всё». Начиная открытием справочников, заканчивая проведением документов. При этом, интернет и сеть работают нормально.
Я начал снимать показатели производительности на серверах СУБД и AOS. Также был запущен технологический журнал с отборами по исключениям и запросам длительностью более 15 секунд. 1С ЦУП отсутствует.
Показатели сервера приложений были в норме. Счетчики сервера БД показали, что всё в норме, кроме очереди к дисковой подсистеме:

На данном скриншоте видна средняя длина очереди к дискам = 2.912. При дальнейшем мониторинге был средний показатель 6 и даже 8.
Фирма 1С рекомендует, чтобы очередь к дискам не превышала 2* количество дисков, работающих параллельно.
Также по данным счетчикам удивило крайне низкое использование оперативной памяти.
По данным лога технологического журнала исключительных ситуаций, влияющих на производительность не было. Однако, было много запросов, которые выполнялись дольше 15 секунд. При анализе был замечен 1 запрос, который выполнялся очень часто и очень долго:
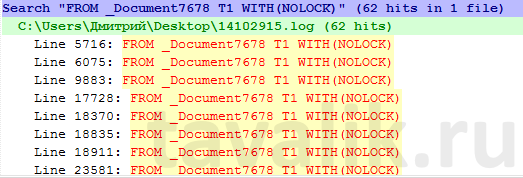
Из скриншота видно, что запросы из этой таблицы за 1 час 62 раза выполнялись дольше 15 секунд. Также виден хинт WITH(NOLOCK). 1С применяет этот хинт при чтениях вне транзакции, чтобы дополнительно исключить влияние каких-либо блокировок. Отсюда вывод – данный запрос выполняется так долго не из-за проблем параллельной работы, а потому что он «тяжелый» и диски не справляются.
Монитор активности MSSQL также подтвердил, что данный запрос находится в «топе» тяжелых запросов. А запрос следующий:
SELECT ... FROM _Document7678 T1 WITH(NOLOCK) ... WHERE (T1._Fld7852RRef = @P5)
Т.е. простейший запрос с отбором по полю. В данной таблице находится ~800000 записей. Отбор идет по полю, не входящему в кластерный индекс, соответственно сканируется вся таблица.
Кстати, в мониторе активности можно посмотреть план запроса и там он как раз предлагает добавить некластерный индекс по данному полю, что я и сделал. Дышать сразу стало легче, очередь к дискам упала. Таким же образом я добавил еще 2 индекса.
Этими средствами я снял симптомы, но причину не устранил, т.к. раньше (на старом оборудовании) всё работало хорошо. Я зашел в свойства MSSQL и увидел причину использования малого количества памяти:

СУБД было отведено только 8ГБ памяти. Соответственно, такие тяжелые таблицы по 800000 записей система не могла кэшировать в памяти и все эти запросы вытягивали данные напрямую с дисков. Отсюда и была их аномальная загрузка.
Выставим доступную память на 30 ГБ из 32х возможных проблемы окончательно ушли. В дальнейшем, мы удалим эти индексы из СУБД и добавим их средствами 1С:

Всем спасибо за внимание.